会計ソフトfreeeのデータをBigQueryに連携する
・会計ソフトは、売上や経費の計上、入金と請求の消込みなど、経理業務を効率化できる
・ただ、会計データを横断的に分析したり、次の施策検討に活用するには機能が十分とは言えない
・freeeはAPIを公開しており、取引データをGoogle Cloud Run Functionsで取得し、BigQueryに同期できる
・OAuth認証で取得したトークンはSecret Managerで安全に管理する
会計ソフトは売上や経費の計上だけでなく、消込み(取引先からの入金と請求を名寄せする処理)もできる便利なSaaSです。
経理業務が劇的に効率化します。
ただ、会計データを分析したり、そこからネクストアクションを検討することは、まだまだ十分ではありません。
会計データをダウンロードして、BIに取り込めば分析できますが、そもそもデータを分析に適した形式でダウンロードできない場合もあります。
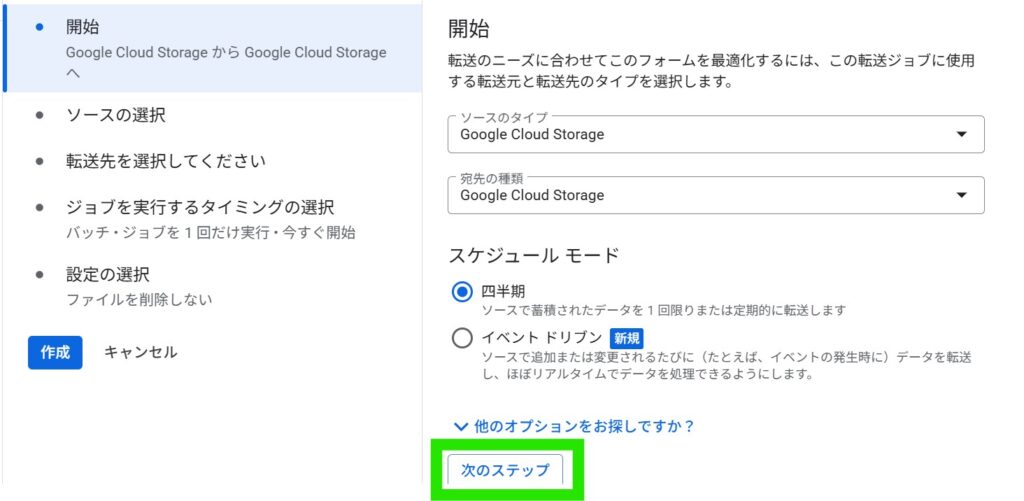
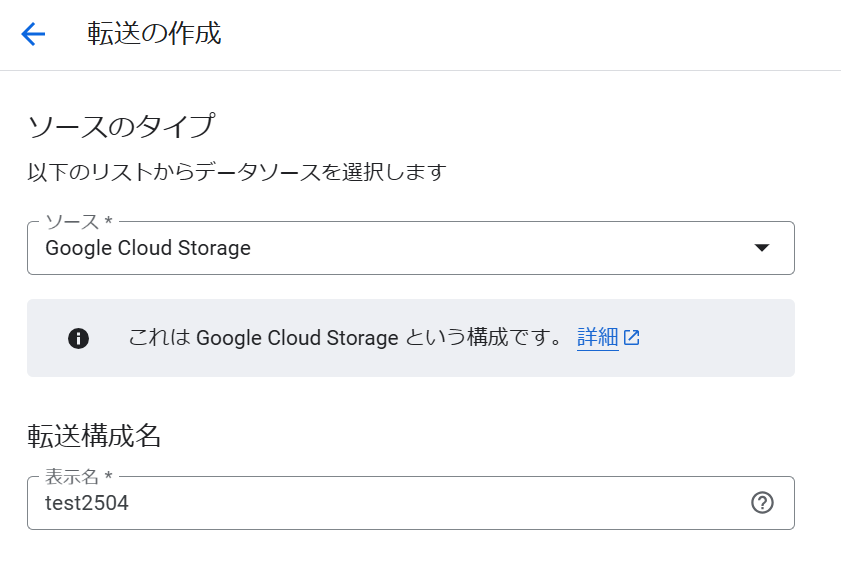
そこで、会計ソフトfreeeを例に、データをBigQueryに連携してみました。
会計ソフトfreeeのAPIは公開されている
freeeのホームページを検索すると、APIリファレンスが公開されていました。
アカウントや申請情報、銀行口座連携など、たくさんありそうです。
リファレンスを下にスクロールすると、Deals 取引(収入・支出)というものを見つけました。
内容を見ると、おそらくこれをBigQueryに連携すれば、ある程度のデータが見れそうです。
-1024x634.jpg)
Deals 取引(収入・支出)のAPIリファレンス
発生日や金額、収入・支出フラグなど、取引の詳細なデータを取得できます。
Google Cloud Run Functionsでfreeeに接続する
freeeの取引データは、Google Cloud Run Functionsで接続できます。
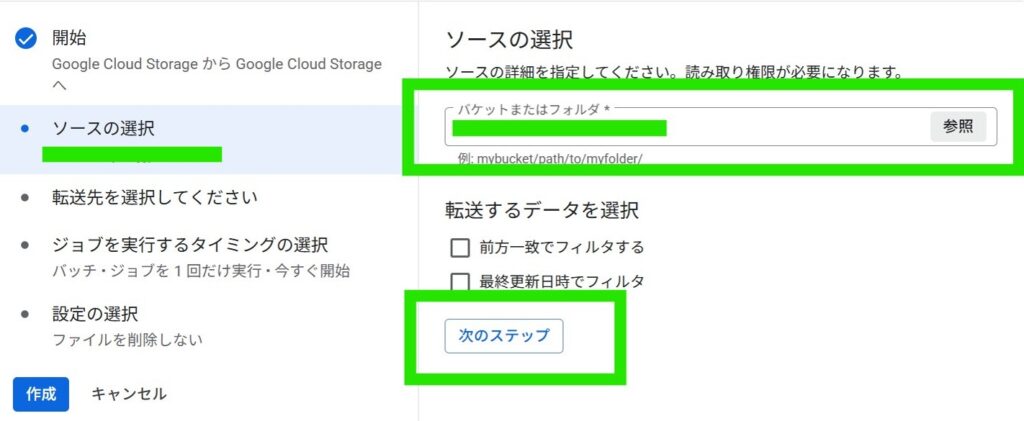
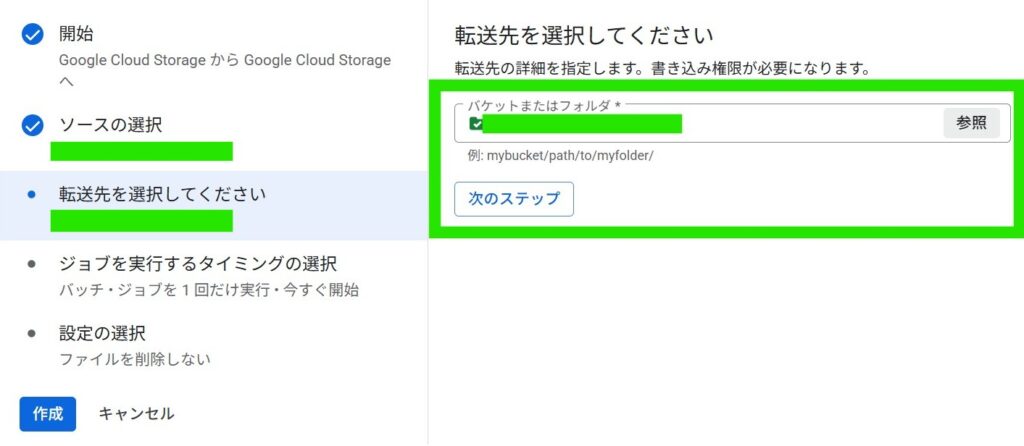
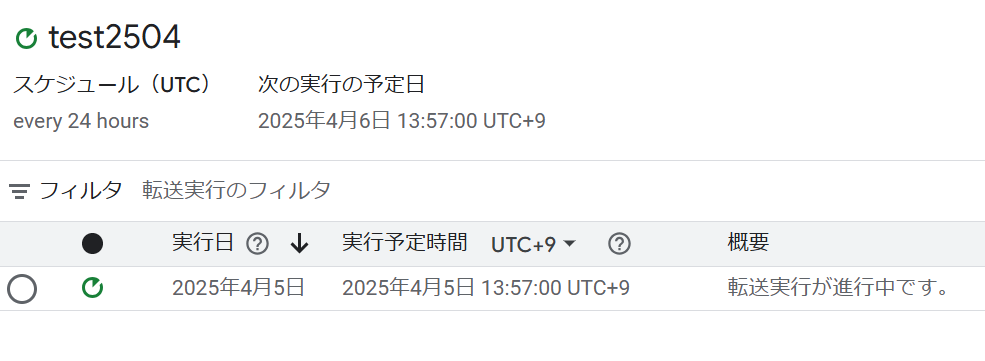
freeeのOAuth連携を行い、freeeの取引(deals)を取得して、BigQueryにテーブルとして同期します。
freeeの認可画面へリダイレクトしてOAuthを開始し、freeeから返ってきたcodeを使ってtoken交換し、refresh_tokenをSecret Managerに保存します。
初めて接続した時は、Secret Managerを使わなかったのですが、最終的に使うことになった理由は後述します。
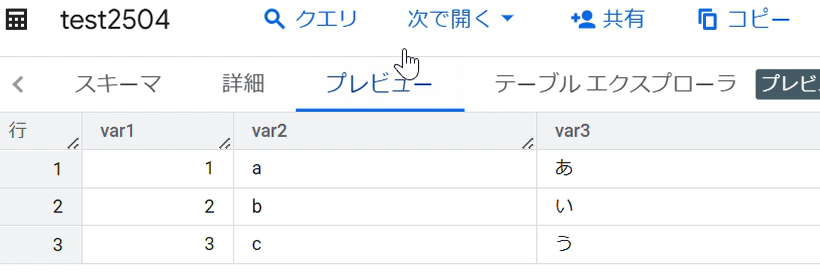
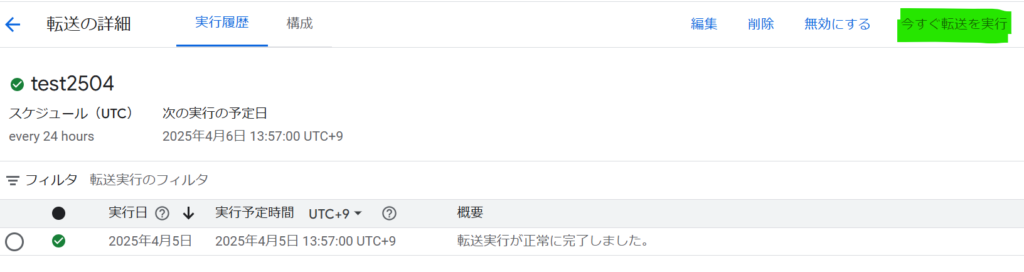
そして、freee APIを叩いてデータを取得し、freeeの取引一覧(deals)を期間指定で全件取得して、BigQueryに同期します。
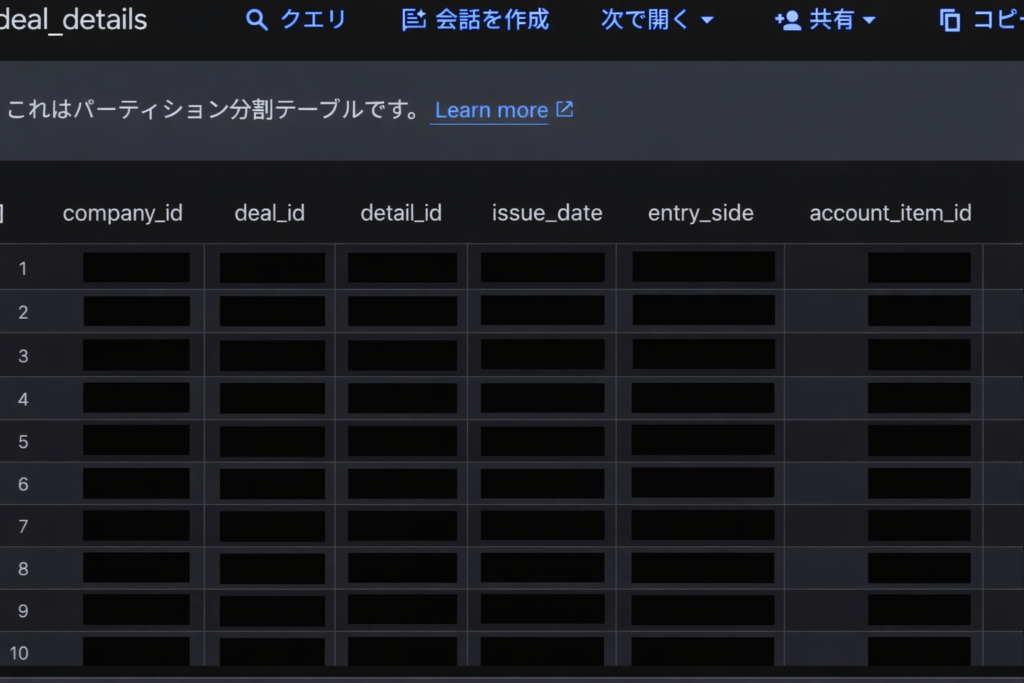
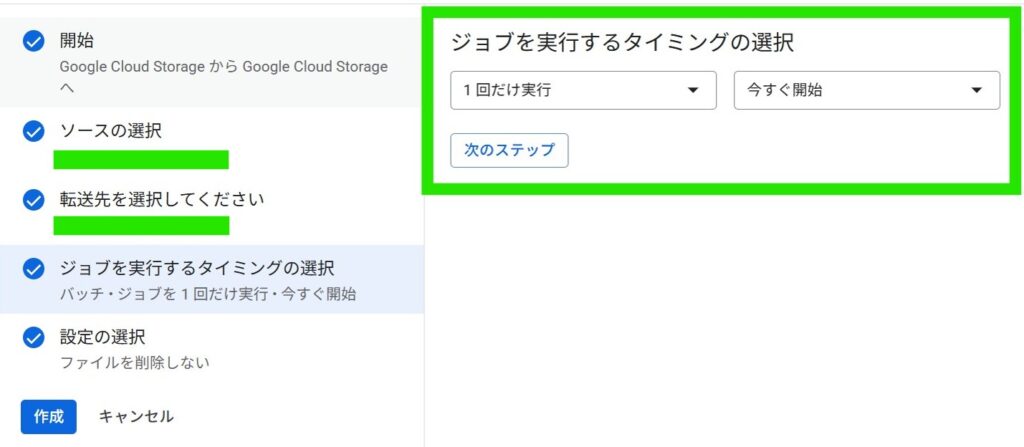
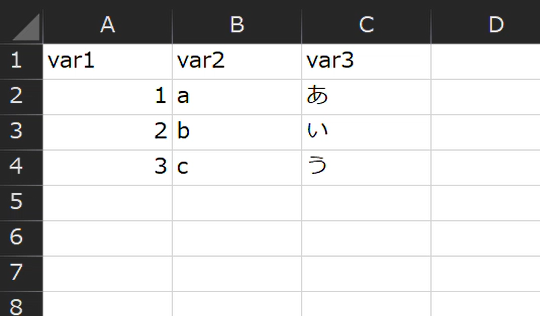
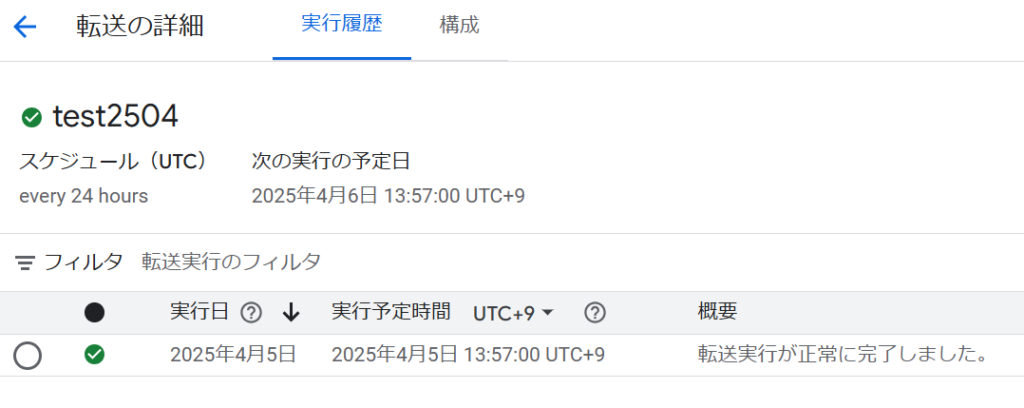
BigQueryに同期したfreeeの取引データ
トークンのエラー沼にご注意
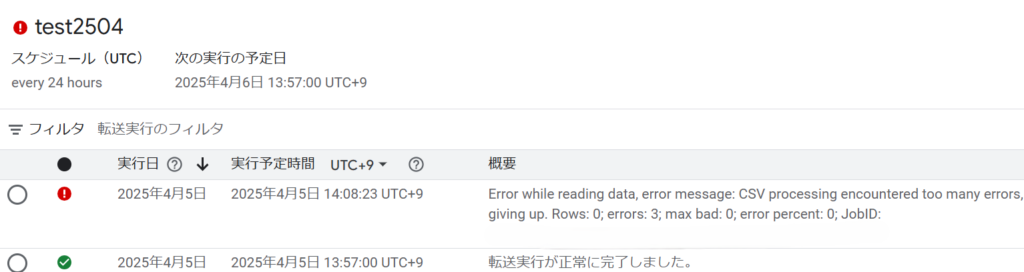
連携は成功しましたが、翌日にデータを更新すると、エラーになりました。
{'error': 'invalid_grant', 'error_description': '指定された認可グラントは不正か、有効期限切れか、無効か、リダイレクトURIが異なるか、もしくは別のクライアントに適用されています。'}
どうやら認証エラーが発生しているようです。
いろいろ検証したところ、トークンが原因でした。
refresh_tokenでaccess_tokenを取得し、access_tokenでfreee APIを呼ぶ流れになっていますが、refresh_tokenを使ってaccess_tokenを取得すると、レスポンスに新しいrefresh_tokenが返ってくることがあります。
その場合、古いrefresh_tokenを使うとエラーになります。
refresh_tokenを使い回すことはできず、最新のrefresh_tokenを常に保持しなければなりません。
refresh_tokenは、APIを実行する度に変わるとは限りません。
そのため、APIを実行し、レスポンスに新しいrefresh_tokenが含まれていたら、そのtokenを保存して更新することでエラーを回避します。
Cloud Runの環境変数にrefresh_tokenを固定せず、Secret Managerをrefresh_tokenの台帳として使うように設計することでエラーを回避できました。
Google Cloud開発お承ります
datacompanyでは、お客様のご予算・環境に応じたクラウド開発を承ります。
お困りごとがございましたら是非ご相談ください。