BigQuery Data Transfer Service(DTS)の限界
・誰でも簡単にノーコードでBigQueryにデータ連携できることが魅力的
・例えば、Google Cloud Storageと連携すれば、CSVをアップロードする度にBigQueryも自動更新
・ただし、CSVのカラムを増やしたりするとエラーになる Excelも未対応
・工数はかかるが安定運用や長期的な工数を考慮すると、Cloud Runでフルスクラッチ開発がベター
・Cloud Runなら、カラムが変動しても、動的にBigQueryのテーブルを更新できる
BigQueryのようなDWHに社内外データを集約したい時に役立つのがBigQuery Data Transfer Service(DTS)です。
馴染みのない名前かもしれませんが、Google広告のデータをBigQueryに連携する時など、知らないうちに利用していたという方も多いと思います。
DTSは、たびたびアップデートされており、連携できるサービスも多数あります。
Google広告やYoutube、Google Cloud Storage(GCS)等のGoogle系サービスをはじめ、AWS(S3・Redshift等)やTeradata、最近ではSalesforceやMeta広告のプレビュー版が提供されています。
Salesforceのプレビュー版についてはこちらの記事もお勧めです。
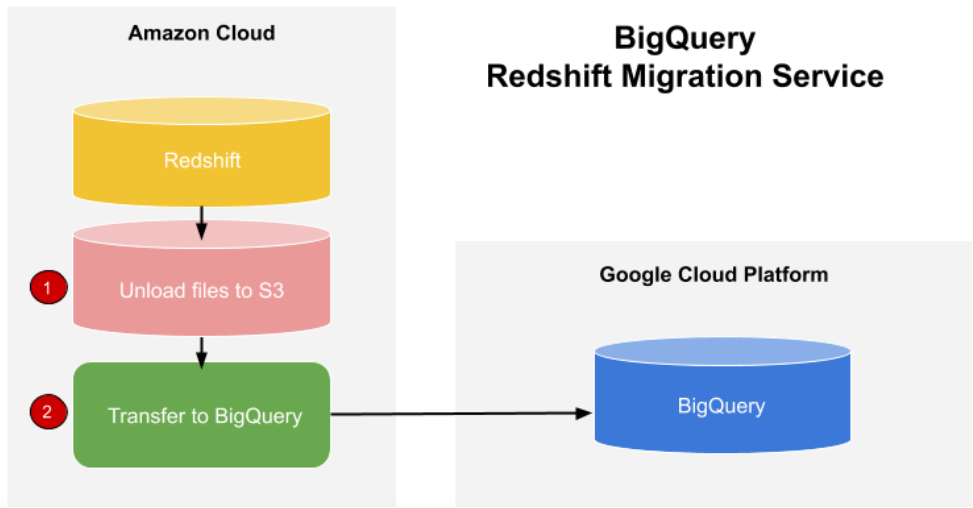
AWS(Redshift)とBigQueryの連携についてはこちらの記事もお勧めです。
DTSのユースケース Google Cloud Storage(GCS)とBigQueryを連携
DTSで、よく使われているケースとして、GCSとBigQueryの連携があります。
特に、KPIをトラッキングする企業様において、目標値や実績等をCSVで管理されており、それらをBigQueryに連携して、他データと統合分析する場合に役立ちます。
実装もとても簡単です。
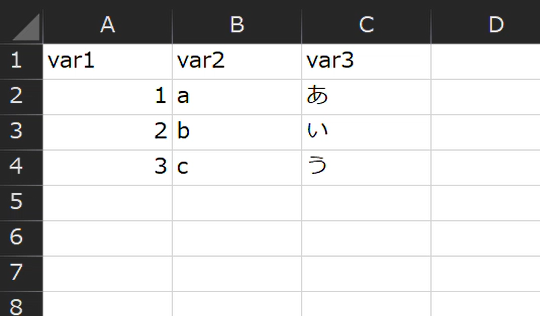
任意のCSVを用意します。1行目に変数名、2行目以降にデータを入力します。
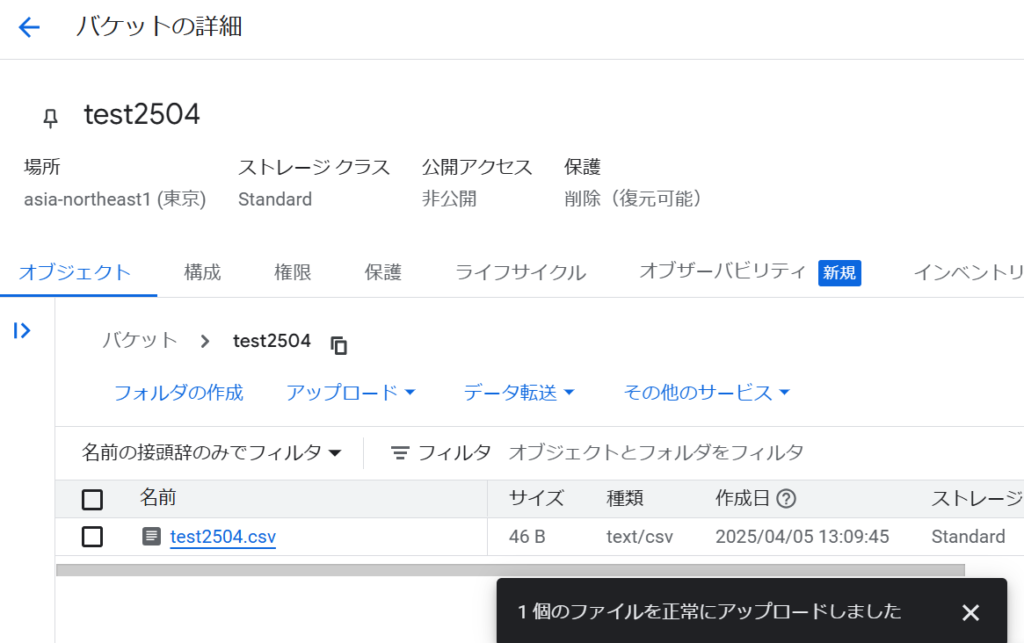
GCSの任意のバケットにアップロードします。
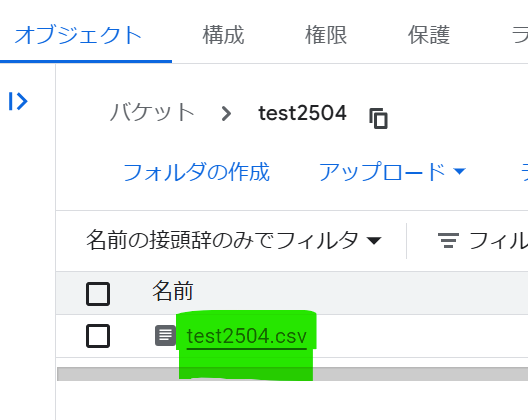
アップロードしたCSVをクリックします。
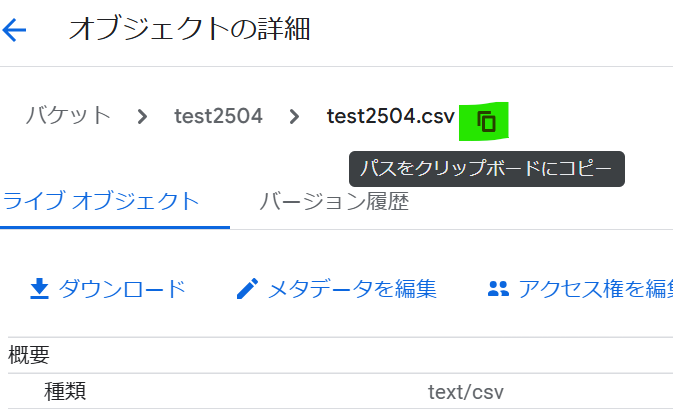
このマークをクリックし、パスをコピーします。
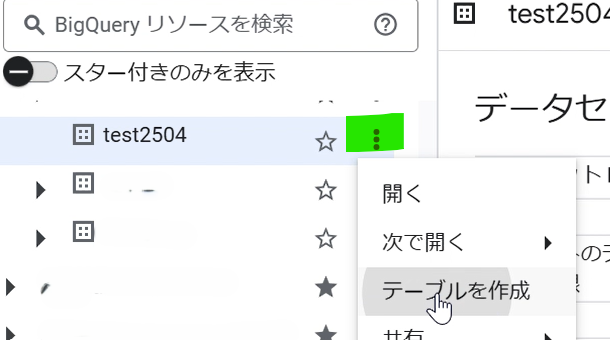
BigQueryをひらきます。データセット横のマークをクリックし、テーブルを作成します。
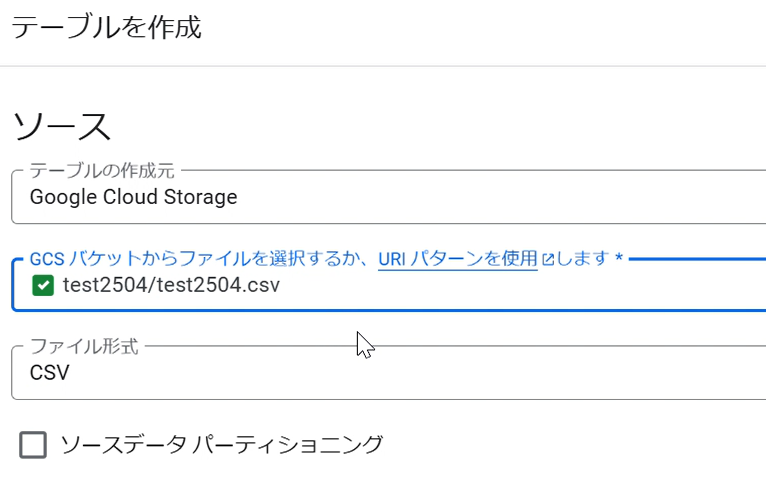
テーブルの作成元「Google Cloud Storage」を選択し、GCSバケットの欄に、コピーしたGCSのパスをペーストします。
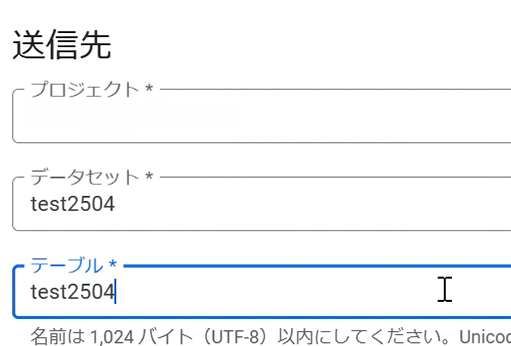
テーブルに任意の名前を入力します。画像加工によりプロジェクトがブランクになっていますが、プロジェクトはご自身のプロジェクト名が入ります。
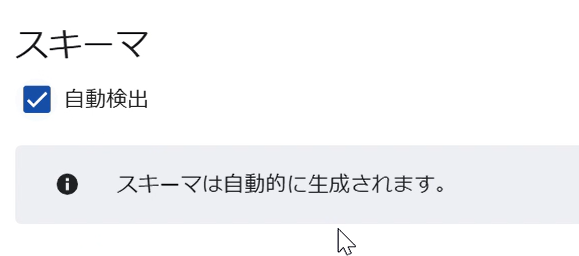
スキーマをお好みで設定します。複雑なデータでなければ自動検出で可能です。
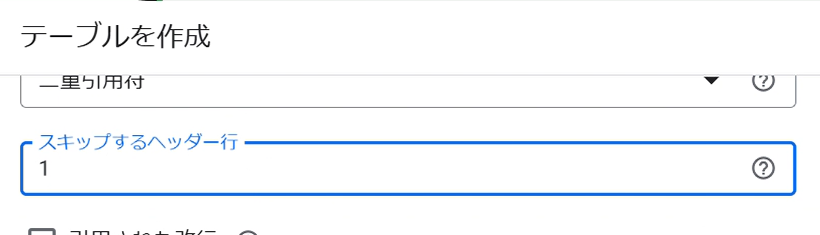
1行目をスキップし、変数名がデータとして取り込まれないようにします。
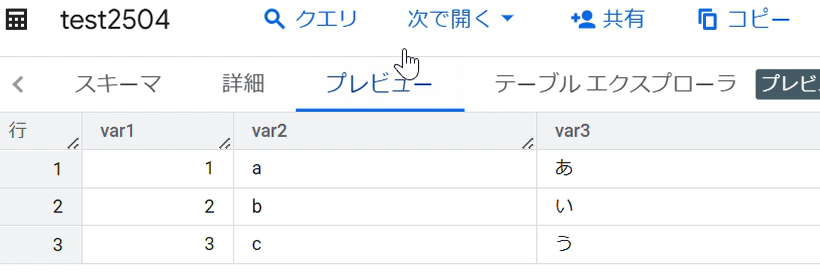
作成ボタンをクリックし、テーブルを確認します。成功すれば、このようにCSVが取り込まれます。
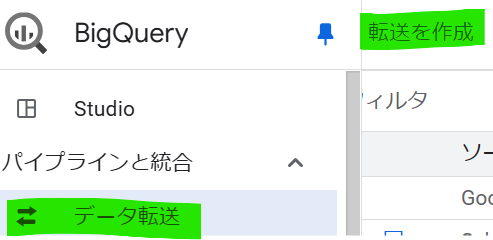
BigQueryの画面左「データ転送」→「転送を作成」をクリックします。
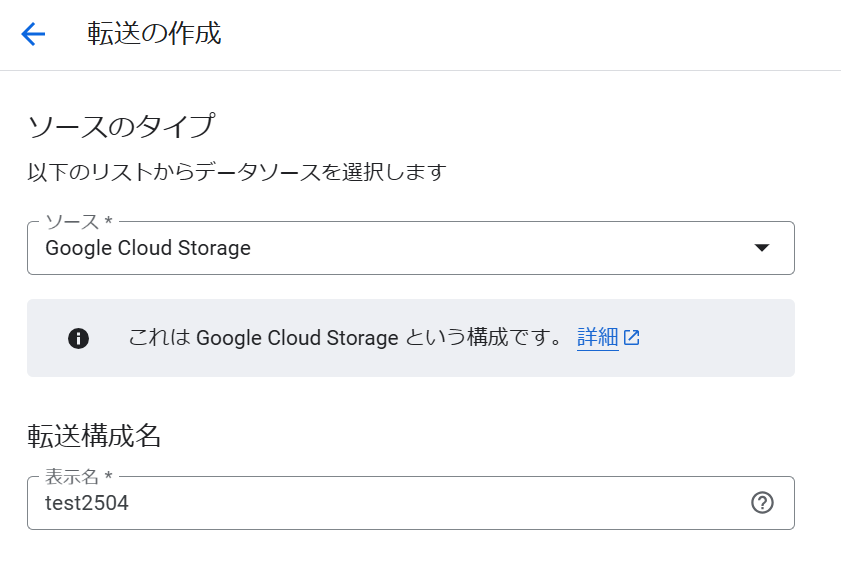
ソース「Google Cloud Storage」を選択し、任意の転送構成名を入力します。

データセットやGCSのCSV等を同じ要領で設定し、保存をクリックします。
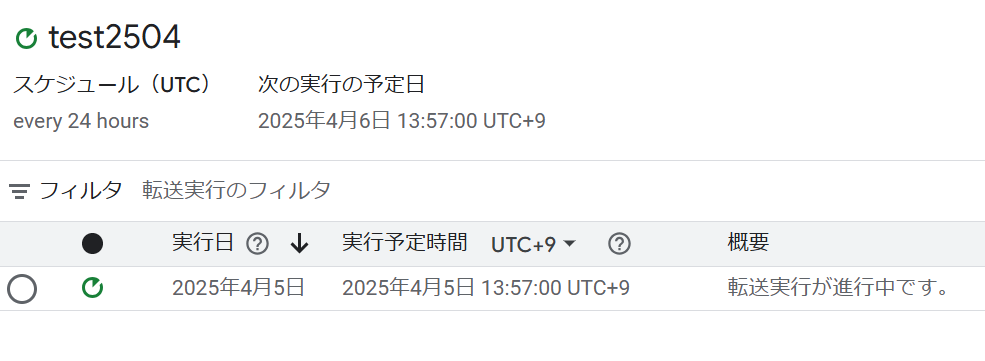
設定が完了すると、画面が切り替わり、転送を開始します。
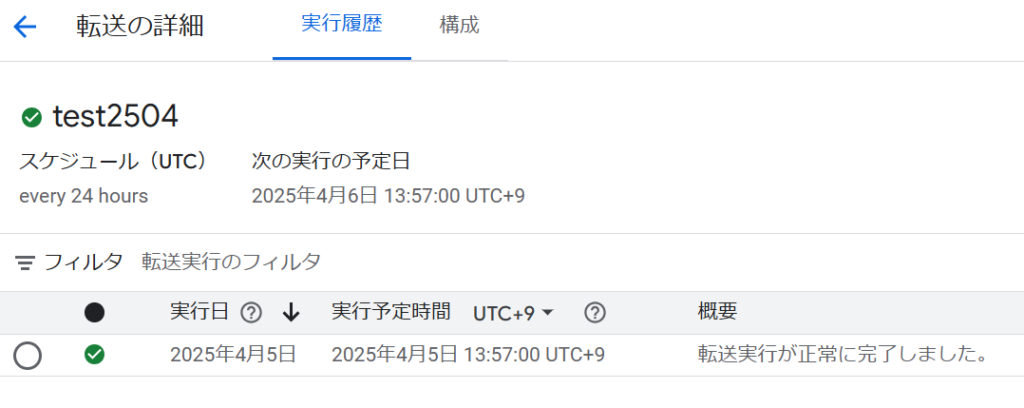
成功すると、緑色のチェックマークが点灯します。
DTSには限界もある
このように設定すると、CSVのレコードが増えても、GCSにCSVをアップロードしておけば、設定したタイミングでBigQueryに自動で反映します。
KPIをHourlyや日次で管理している企業様の場合、ノーコードで簡単な操作だけで、このようなデータ連携を構築できます。
しかし、DTSには限界もあります。
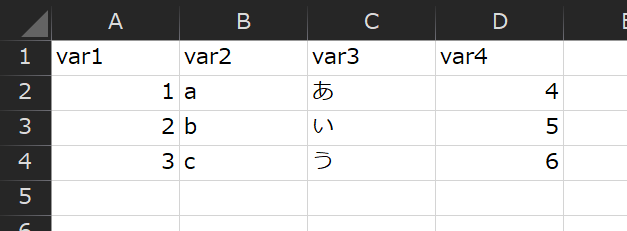
例えば、先ほどのCSVのD列にVar4を追加します。
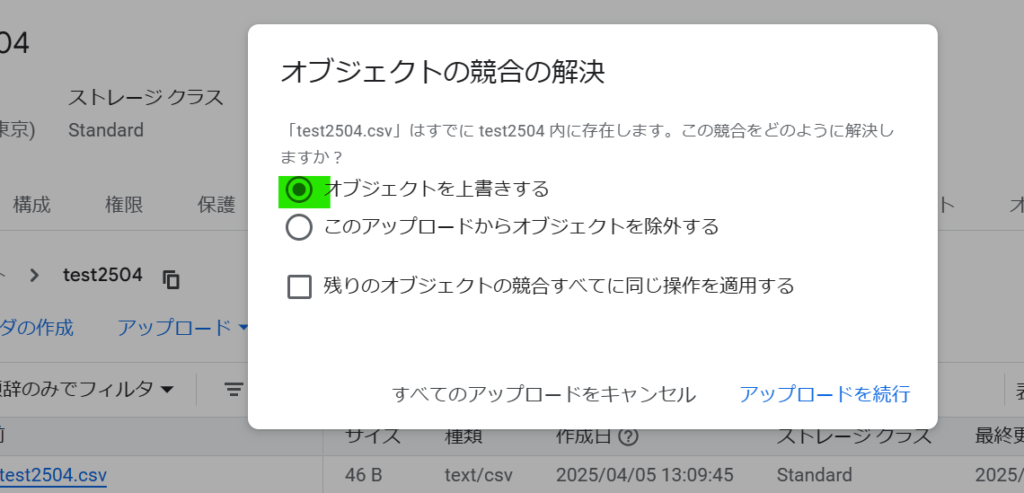
GCSにアップロードし、上書きします。
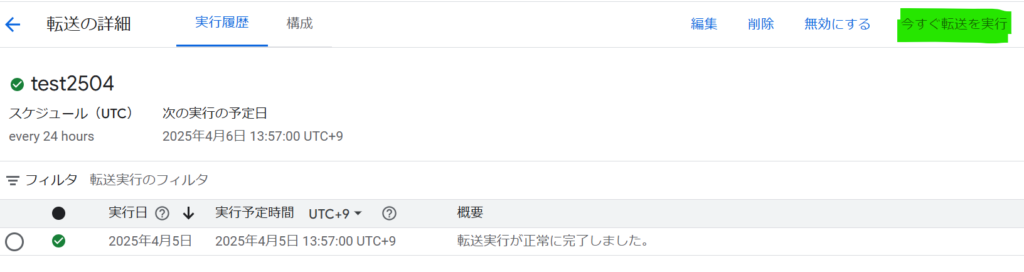
DTSの画面で、今すぐ転送を実行します。これによりGCSのデータがBigQueryに手動で反映できます。
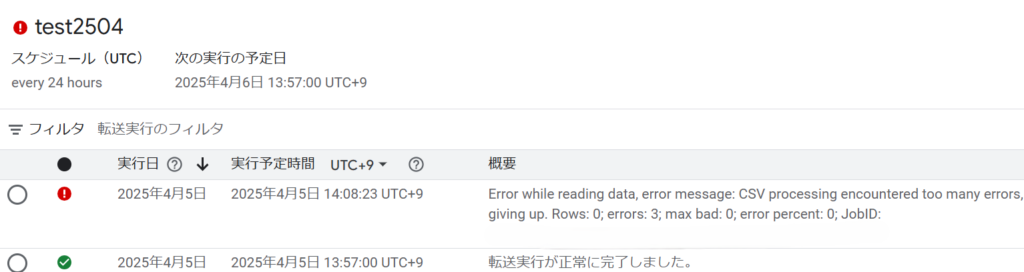
しばらくすると、処理がエラーになります。
エラーの内容です
Error while reading data, error message: CSV processing encountered too many errors, giving up. Rows: 0; errors: 3; max bad: 0; error percent: 0; JobID:...省略
many erros たくさんのエラーが発生し、正常に読み込まれたRowsレコードは0行です。
これは、CSVのカラムを増やしたことが原因です。
DTSは、CSVの仕様が変わると、このようなとエラーになります。
弊社のお客様には、社内データをCSVで管理されており、CSVのカラムを定期的に増やす企業様もおられます。
また、Excelで管理されている企業様もおられます。
そのようなケースの場合、DTSでは対応できません。
Google Cloud Run Functionsのフルスクラッチでカスタマイズ対応
このようなケースの場合、初期工数はかかりますが、Google Cloud Run Functionsのフルスクラッチ開発がベターになります。
Cloud Run Functionsなら、カラムが増えてもエラーにならず、動的にBigQueryのテーブルを更新できます。
特定セルの値だけBigQueryに取り込むことも可能で、Excelも取り込めます。
安定運用や長期的な工数軽減、柔軟に対応したい場合等を考慮すると、DTSより優れている場合が多いと思います。
Cloud Run FunctionsはPythonに対応。イベント駆動で様々なケースに応じた処理がサーバレスにできる。
Google Cloud開発お承ります
datacompanyでは、お客様のご予算・環境に応じたクラウド開発を承ります。
お困りごとがございましたら是非ご相談ください。