Googleのチュートリアル通りに進めるとエラーになるときの対処法
・エラーメッセージから仮説を立て試す
・チュートリアルに記載のないことも試す
・特に、プレビュー環境の場合、チュートリアルが実態にそっていない傾向があることを知っておく
※執筆当時の情報です
前回は、Cloud Data Fusionを停止して年間200万円コスト削減したことをご紹介いたしました。
今回は、Amazon RedshiftからGoogle BigQueryへデータ連携を事例に、Google Cloudのチュートリアル通りに進めてもエラーになる場合の対処方法をご紹介いたします。
前回のお話は以下よりご覧いただけます。
Googleの公式サポートを使わずに解決できればベター
Google Cloudのチュートリアルは、ほぼ完全に整備されており、チュートリアルを進めることで大抵のことは解決します。
あまり経験していませんが、チュートリアル通りに進めてもエラーになる場合があります。
そのような場合、Google Cloudの公式サポート(有償)を頼ることになりますが、この事例で取り上げるCloud Data Fusionの日本サポートチームはインドのバンガロールにあります。
時差や英語でのコミュニケーションに加え、オンライン会議で画面操作を試す→エラー→再操作→再エラー・・・を繰り返すなど、効率が良いとは言えず、とても多くの工数を消費してしまいます。
また、事前にチケットで、プログラムや出力結果を送っているものの、担当チームやメンバーによっては、会議で初めて内容を確認されたり、仮説を持ち寄らず、場当たり的に複数人から質問攻め・操作を求められる・・・といったこともありました。
なるべく公式サポートを使わずにエラーを解決できるのがベターですので、今回のお話が皆様にもご参考になれば幸いです。
Amazon RedshiftとGoogle Cloudの連携
クライアント様がAWSからGoogle cloudにクラウド移管をご検討中で、AmazonのDWHであるRedshiftから、Google CloudのDWHであるBigQueryにデータ移管を準備していました。
RedshiftからBigQueryに連携する方法はいくつかありますが、今回のご要望の場合、BigQueryのデータ転送APIであるBigQuery Data Transfer Service(DTS)を使うことが最も簡単です。
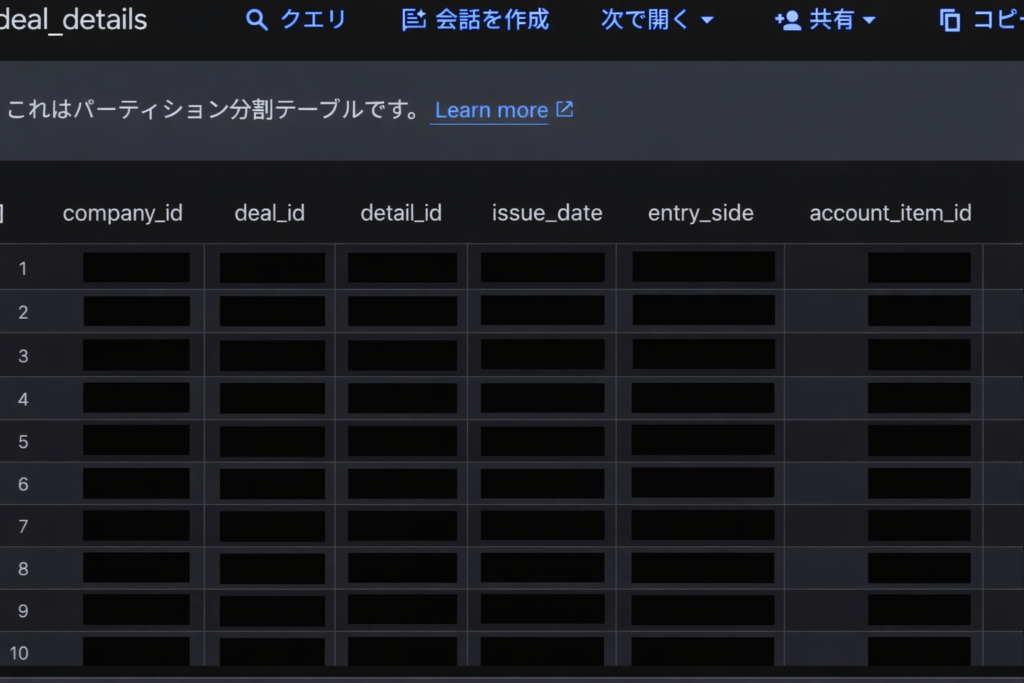
DTSによるデータ連携は、Redshiftへの直接連携ではなく、下図のようにAWSのクラウドストレージS3を介して連携されます。
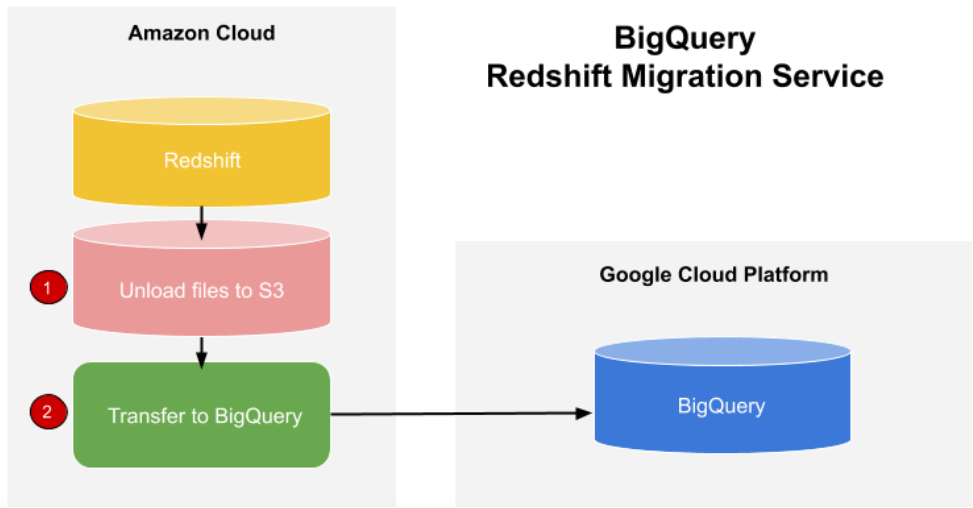
DTSでRedshiftに連携すると、S3を介して連携。S3はステージング領域として使用。
Amazon Redshift からスキーマとデータを移行する
この設定には、AWS側の情報やアクセス権限等が必要です。
クライアント様は代理店様を通じてAWSをご契約されており、AWSの管理も代理店に任せておられました。
クライアント様にお願いし、代理店様から情報一式をいただきましたが、Amazon IAM ユーザーの情報が見当たりませんでした。
クライアント様に確認したところ、IAMユーザについてはクライアント様もお持ちでなく、わからないとのことでした。
そこで、代理店様に確認したところ、代理店様の社内規定により、クライアント様や弊社にはIAMユーザーを引き渡せないとの回答でした。
一般的には、委託元もIAMユーザを使えるのですが、クライアント様と代理店様の契約上の理由とのことで、予定していたDTSによるデータ連携を断念しました。
DTS以外でRedshiftとBigQueryを連携
DTS以外でもRedshiftとBigQueryを連携できます。
網羅できておりませんが、例えば、以下の方法があります。
一番上のDTSは、AWSのIAMユーザーが必要なため、断念した方法です。
2つ目のBigQuery Omniは、AWSのS3を外部データソースとしてBigQueryから参照し、SQLを実行できるものです。
RedshiftからS3へのデータコピーは必要ですが、BigQueryへのデータコピーは不要です。
しかし、この方法もAWS IAMユーザーが必要で、今回の要件を満たしません。
また、現在、東京リージョンに非対応です。
クライアント様にご相談したところ、納期が最速で、安定稼働できることをお求めでしたので、Cloud Data Fusionで進めることになりました。
Cloud Data Fusionは、バックエンドでクライアント様専用の仮想サーバを立ててパイプラインを構築するようなもので、時間課金のETLツールです。
1年間利用すると、現在の為替レートで約200万円課金されますが、今回のご要望のように、クラウド移管に際して一時利用であれば、デフォルトで用意されているGoogle Cloud の月間無償枠で利用できます。
チュートリアル通りに進るとエラーになる
チュートリアルを見ると、あらかじめ、AWSのJDBCドライバーをCloud Data Fusionにアップロードしておく必要があります。
HostやPortなど、その他の必要な情報をクライアント様・代理店様から入手し、設定しました。
Cloud Data Fusionでは、設定が正しいか、デプロイ前にVaridateボタンを押下すると検証できます。
ところが、ボタンを押下したところ、見慣れないエラーが出ました。
Read timed out
一時的なものかと思い、何回か試しますが、結果は変わりません。
AWS側のマニュアルを見ると、JDBCドライバーのオプションとして、timeoutに関する設定を変更できるようです。
そこで、Cloud Data Fusionでこれらの変数を設定して、timeoutを無効にしました。
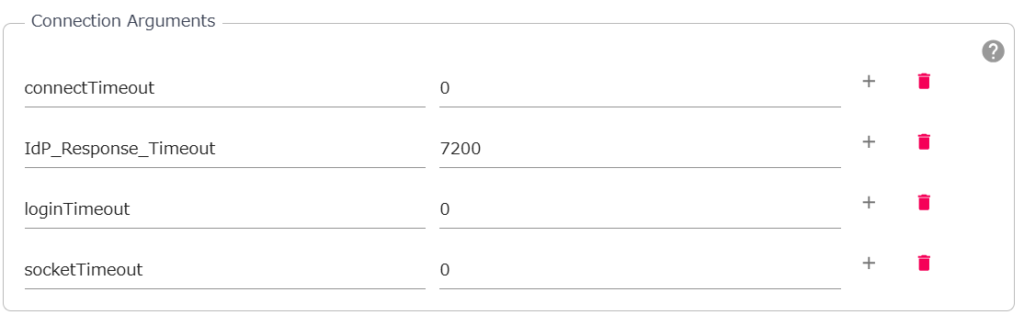
0(無効)、7200秒(2時間)でtimeoutパラメータを設定
しかし、結果は変わりません。
Read timed outでタイムアウトエラーになります。
チュートリアルどおりに進めているのにデプロイできずエラーになります。
ここで、解決策が尽きてしまいました。
エラーメッセージから仮説をたて試す
Read timed outというエラーメッセージからすると、Redshiftにデータを参照している際に発生するエラーのようです。
一般的には、データ容量が大きくなるほど、連携に必要な時間も長くなります。
カラム(列)が増えると、データ量も急激に増え、時間も長くなります。
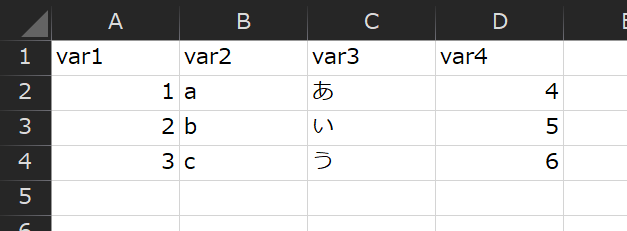
そこで、1カラムだけ連携したところ、Varidateが成功し、デプロイできました。
次に、カラムを2カラムで試すと、Read timed outのエラーになりました。
どうやら2カラム以上だとTimeoutするようです。
そこで、レコード数がどの程度までなら、2カラムでもデプロイできるか確認することにしました。
10レコード程度で2カラムのサンプルデータをRedshiftに用意し、Varidateしたところ、Timeoutしました。
デプロイに成功した1カラムのデータは、1000レコード以上あります。
Timeoutした2カラムのサンプルデータは10レコードです。
このTimeoutエラーは、データ量ではなく、設定など別の理由が原因と仮説を立てました。
どの設定が原因か特定するため、1つずつ設定内容を変えてみることにしました。
例えば、JDBC接続に必要なAWS側のパスワードを、故意に1文字減らしました。
そうすると、エラーメッセージが変わり、Timeoutは表示されません。
これにより、パスワードは正しく、パスワード以外の方法が原因であるこことがわかります。
このような地味なチェックを進めたところ、Output Schemaを自動判定させず、手動入力してからVaridateすると、デプロイできました。
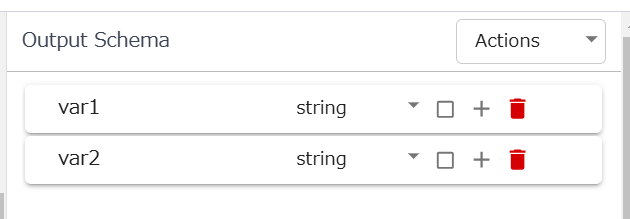
チュートリアルではVaridateで自動判定するOutput Schema。今回の事例では、この機能が原因でエラーに。
チュートリアルでは、手動入力ではなく、Varidateで自動判定させますので、思いもよりませんでした。
Google Cloudのチュートリアル通りに進めてもエラーになる場合、このように仮説をたてて進めると突破できる可能性があります。
プレビュー環境の場合、チュートリアルが実態にそっていない傾向がありますので、より一層ご留意ください。
・エラーメッセージから仮説を立て試す
・チュートリアルに記載のないことも試す
・特に、プレビュー環境の場合、チュートリアルが実態にそっていない傾向があることを知っておく
Google Cloud開発お承ります
datacompanyでは、お客様のご予算・環境に応じたクラウド開発を承ります。
お困りごとがございましたら是非ご相談ください。
お問い合わせフォーム

-1024x634.jpg)