Google Cloud Run Functionsで処理がループする時の対処法
・ETLでもよく使われるGoogle Cloud Run Functions(Cloud Run 関数)
・例えば、Google Cloud Storageに保存したエクセルをBigQueryに取り込んでテーブル化できる
・ただし、大量のエクセルを処理する等で、処理済みのエクセルが再処理され異常ループに陥りやすい
・処理済みのエクセルを退避フォルダへアーカイブすることでループを回避できる
・アーカイブ済みファイルのSkip等の処理を追加するとベター
ETLでGoogle Cloud Storageに保存したエクセルを、BigQueryでテーブル化する時に役立つのがGoogle Cloud Run Functions(Cloud Run 関数)です。
Google Cloud Run Functionsは最近になって正式リリースされたもので、Google Cloud Functionsと聞けば、馴染みのある方も多いと思います。
現在、Google Cloud Functionsという製品ブランドは廃止され、Cloud Run Functionsという名前になりました。
そのCloud Run Functionsには第1世代と第2世代があり、いわゆる旧Google Cloud Functionsは第1世代にあたります。
第2世代が、今日ご紹介するCloud Run Functionsというわけです。
もし、これから、ETL等でご利用される場合、Cloud Run Functions(旧Google Cloud Functionsの第2世代)の利用を強く推奨いたします。
第1世代は制約も多く、使えるメモリー等のパフォーマンスも劣ります。
大容量データを、複雑な処理でバッチ化する場合、第1世代ではタイムアウト時間が最大540秒と短く、処理が終わらずに停止するケースがよくあります。
第2世代なら、ハイパフォーマンスで処理できるうえ、タイムアウト時間も最大900秒まで設定できますので、様々なビジネス課題に対応することが可能です。
今日は、その最新のGoogle Cloud Run Functionsのお話です。
Cloud Run Functionsの処理が異常ループする
例えば、Google Cloud Storage「バケットA」にエクセルが100個あるとします。
100個のエクセルを一括でBigQueryにテーブル化したい時、Cloud Run Functionsが便利です。
たいていの場合、以下のようにsource_bucketを指定し、1回の実行で済むように、エクセルを1つ処理して、また次のエクセルを処理・・のようにループさせると思います。
#ソースバケットの指定
source_bucket_name = 'bucket_a'
~~~
blobs = list(source_bucket.list_blobs())
for blob in blobs:
source_blob_name = blob.name
~~~
しかし、このまま実行すると、一度処理したエクセルも再実行する異常ループが発生します。
エクセルが少なければ処理できると思います。
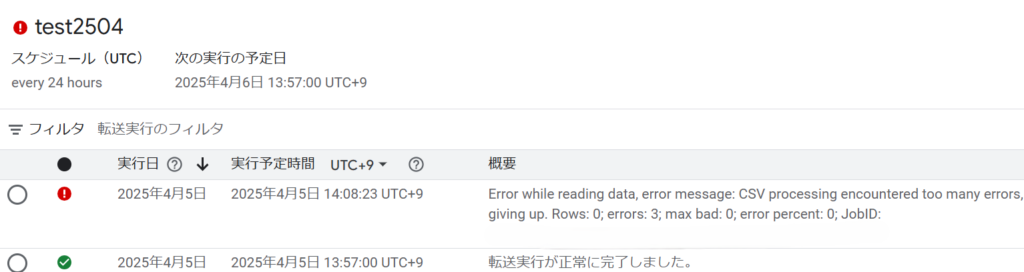
しかし、エクセルが100個あるような場合、この異常ループにより、処理が進まず、Cloud Run Functionsがタイムアウトしてしまいます。
これは、「バケットA」にあるエクセルをすべて処理するまで、Cloud Run Functionsが動き続けるためです。
ファイルが少なければ、異常ループが発生しても、すべてのファイルが処理される場合が多いのですが、ファイルが多い場合、異常終了してしまいます。
やっかいなことに、このように想定外で終了した場合も、Cloud Run FunctionsのエラーログにはErrorが吐き出されないため、LoggingやMonitoringの検知もすり抜けてしまいます。
つまり、未処理であることにユーザが気づきづらいのです。
処理済みエクセルはバケットBへアーカイブ。バケットAからも消す。
このような場合、Google Cloud StorageにバケットBを作り、処理したエクセルをバケットBへコピーしてアーカイブします。
そして、処理したエクセルもバケットAから消します。
これにより、すべてのエクセルは1度しか処理されず、異常ループは解消します。
バケットBへアーカイブせず削除してもかまいませんが、リカバリ等を考慮するとソースファイルは保護するのがベターです。
以下のように構成すると望ましいです。
#ソースバケットの指定
source_bucket_name = 'bucket_a'
#アーカイブバケットの指定
archive_bucket_name = 'bucket_b'
~~~
blobs = list(source_bucket.list_blobs())
for blob in blobs:
source_blob_name = blob.name
~~
#処理済みファイルをアーカイブバケットにコピー
archive_bucket = storage_client.get_bucket(archive_bucket_name)
archive_blob = archive_bucket.blob(source_blob_name)
source_bucket.copy_blob(blob, archive_bucket, source_blob_name)
# ソースバケットから元ファイルを削除
blob.delete()
アーカイブ済みファイルのSkip等の処理を追加するとベター
他にも、次のような処理を追加するとベターです。
アーカイブ済みファイルのSkip処理を追加
アーカイブバケットを参照し、アーカイブ済みのファイル名をチェックします。
アーカイブ済みのファイルをSkipします。
archive_bucket = storage_client.get_bucket(archive_bucket_name)
archive_blob = archive_bucket.blob(source_blob_name)
if archive_blob.exists():
print(f"{source_blob_name} はアーカイブ済みなのでSkip")
continue
一時ファイル名をユニークにする
デフォルトでは、すべてのファイルの処理で、同じ一時ファイル名を使います。
複数の処理が同時に走ると、一時ファイルが上書きされてしまうことがあります。
【!】この処理を追加する場合、各ファイルを処理した後に一時ファイルも削除して、/tmpディレクトリの肥大化を防ぎましょう!
safe_blob_name = source_blob_name.replace('/', '_')
tmp_source_path = f'/tmp/source_{safe_blob_name}'
tmp_dest_path = f'/tmp/{destination_blob_name}'
Google Cloud開発お承ります
datacompanyでは、お客様のご予算・環境に応じたクラウド開発を承ります。
お困りごとがございましたら是非ご相談ください。
お問い合わせフォーム